Biography
I conduct research at the IMT Atlantique in Brest on hardware and software implementations of signal processing and AI algorithms. I teach computer engineering and digital electronics.
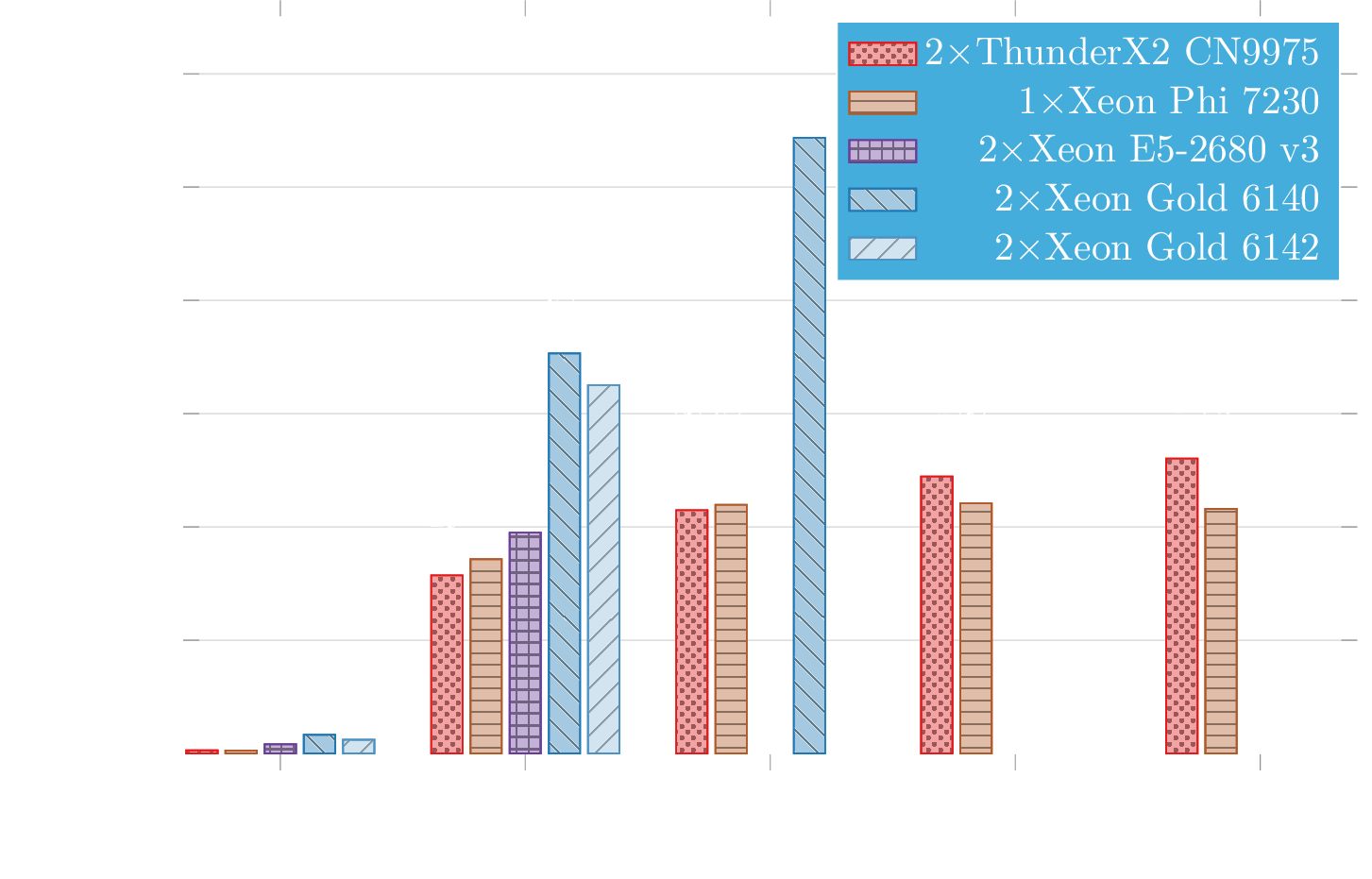
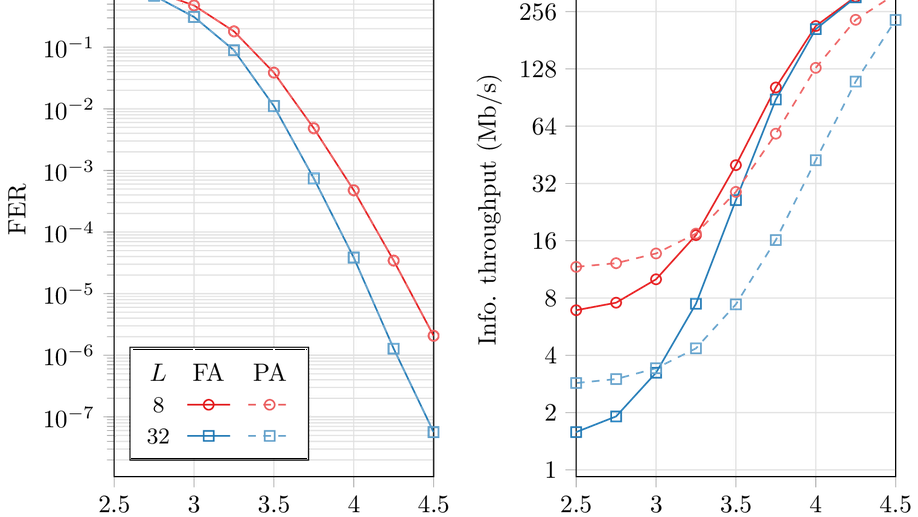
My PhD thesis focused on the implementation of polar codes decoders. I proposed the fastest software implementation of the Adaptive SC List decoding algorithm to date. This implementation is integrated in the AFF3CT toolbox to which I actively contribute.
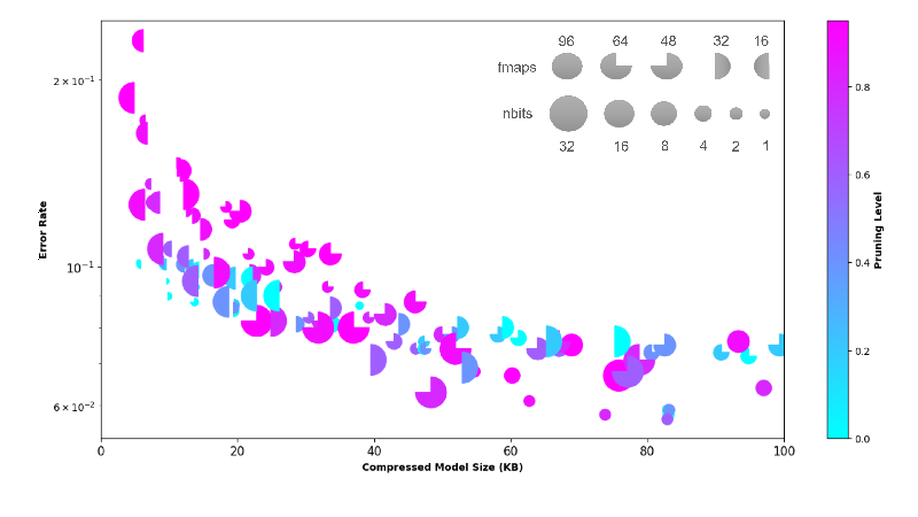
I currently focus on efficient hardware and software implementations of Neural Networks, aiming at low latency and energy efficiency, through multiple industrial collaborations, and as the coordinator of a JCJC ANR project, ProPruNN. We also recently won the AMD Open Hardware Competition with the PEFSL project, a pipeline for the training, compilation, hardware synthesis and deployment of a few-shot learning application on an FPGA SoC. I am also part of the organizing committee of the IEEE International Workshop on Signal Processing Systems (SiPS 2026), which will be held in Bordeaux.
Interests
- Neural Networks Compression
- Embedded Electronics
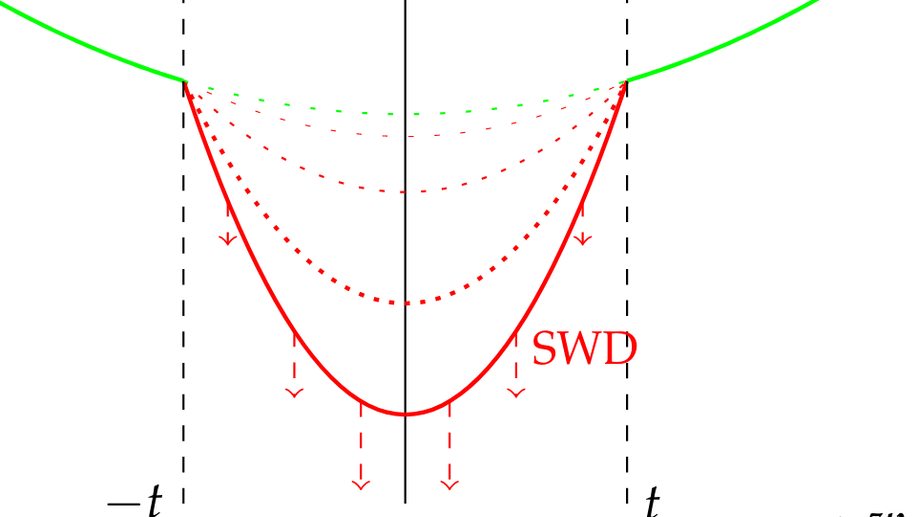
- Channel Coding
- HPC
Education
PhD in Electronics, 2018
Polytechnique Montréal
PhD in Electronics, 2018
University of Bordeaux
MEng in Embedded Electronics, 2015
Enseirb-Matmeca, Bordeaux INP